TCSA忙等待同步错误定位算法论文调研报告
- 论文题目:TCSA: Efficient Localization of Busy-Wait Synchronization Bugs for Latency-Critical Applications
- 作者:Ning Li, Jianmei Guo, Bo Huang, Yuyang Li, Yilei Zhang, Chengdong Li, Wenxin Huang
- 期刊:IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
- 年份:2024
忙等待(Busy Waiting),又称为自旋等待(Spin Waiting),是一种等待机制,常用于并发编程中。它指的是线程在等待某个条件成立时,通过不断地检查这个条件而不是阻塞(sleep or yield),从而占用CPU时间的一种方式。以下是忙等待机制的详细介绍:
- 原理
忙等待的原理是线程在等待某个条件或资源变为可用时,不断地执行一个空循环,反复检查该条件或资源的状态,而不是进入休眠或让出CPU时间。其主要特点是:
- 占用CPU:忙等待的线程会持续占用CPU时间,因为它在不断地检查条件。
- 无需上下文切换:线程不需要被操作系统调度器切换进出运行状态,避免了上下文切换的开销。
- 使用场景
忙等待通常在以下场景中使用:
- 短时间等待:当预期等待时间非常短时,忙等待可以避免线程进入休眠后再次被唤醒的开销。
- 多核处理器:在多核处理器上,忙等待可以使线程在一个CPU核心上忙等,而其他核心继续执行其他任务。
- 锁机制:有些锁实现(如自旋锁)会使用忙等待来实现锁的竞争。
- 优缺点
- 优点
低延迟:由于线程不会被阻塞,条件一旦满足,线程可以立即继续执行,避免了线程切换的延迟。
简单实现:忙等待的实现较为简单,不需要复杂的线程同步机制。- 缺点
资源浪费:忙等待会持续占用CPU资源,即使没有实际的工作要做,这在单核处理器或资源紧张的系统中尤为明显。
竞争加剧:在多线程环境中,忙等待可能会导致更多的线程竞争CPU资源,反而降低系统性能。
摘要
忙等待同步通常用于延迟关键的应用程序中,以确保低延迟。定位忙等待同步的性能错误并不容易,因为我们必须在较长的测量周期中准确找到错误发生的时刻,并同时从众多并发线程中识别出可能的忙等待线程。
本文提出了一种时间调用栈分析(TCSA)的方法,用于高效定位忙等待同步错误。TCSA 可以处理任何编程语言的应用程序,并识别各种忙等待模式,包括自旋锁、链式自旋锁、futex 以及 Java 虚拟机中的 safepoint 检查。
与最先进的方法相比,TCSA 能够有效减少需要检查的记录(如线程和函数)的数量,减少 1 到 3 个数量级。
引言
确保同步的性能对于云系统中的对延迟有极高要求的应用程序(如实时交易和直播流)非常重要。现代应用程序通常使用忙等待同步来实现极低的延迟,并减少线程重新调度和上下文切换的次数。然而,由于多个线程同时访问共享资源时同步序列的争用,关键业务任务的线程未必能及时执行。这可能导致线程在 CPU 上等待,浪费 CPU 周期,甚至导致请求失败或系统崩溃。
在这种多线程执行环境中,几乎所有的性能异常都是非确定性的,并且无法完全重现。首先,在工业环境中只出现一次的性能异常很少被重视,因为它们对业务运营几乎没有后续影响。其次,尽管一些性能异常本质上是非确定性的,但我们仍会遇到在生产环境中高概率发生的许多性能异常。
然而,在实际中定位忙等待同步错误并不是一件容易的事情。首先,几乎不可能直接从性能监控指标中确定忙等待同步争用。其次,工程师通常会收集较长时间段的性能数据来定位错误,需要从较长的数据收集中找到错误发生的时刻,并从大量性能数据中过滤掉与错误无关的线程。
为了帮助定位,已经有大量工作致力于分析不同方面的同步问题。传统方法倾向于报告调用次数超过预设阈值的函数或线程。它们主要通过跟踪特定程序来获取详细的同步信息(例如锁被获取的次数、锁使用的时间和等待锁的时间)来探讨同步问题。还有一些研究人员通过挖掘调用栈信息来进行异常检测,例如比较历史调用信息、可视化调用栈关系以及构建虚拟调用路径。近年来,一些工作采用机器学习和深度学习模型来识别同步,旨在帮助开发人员区分各种类型的同步原语,例如利用无监督学习推断同步。
然而,在实际中使用这些方法存在四个局限性。
- 首先,现有的方法严重依赖于工程师根据业务和领域特定知识分析热点函数,而热点函数不一定在忙等待同步期间执行。这样的分析结果可能不会帮助定位问题,甚至可能误导工程师。
- 其次,这些方法会造成较大的开销。例如,基于 PIN 重复执行程序和检测,或者代码修改,如通过插桩记录所有自旋锁的详细信息。
- 第三,这些方法只能识别特定的忙等待模式或处理特定编程语言开发的应用程序。
- 第四,这些方法要求分析的应用程序的源代码。在许多情况下,检测过程因实际部署而变得更加复杂(如在实际应用场景下,多数用户会拒绝在工业中分享其应用程序的实现细节)。
本文提出了时间调用栈分析(TCSA),这是一种通过时间调用栈(Timing Call Stack, TCStack) 定位忙等待同步性能错误的高效方法。TCSA 仅使用应用程序的函数调用栈来定位忙等待同步错误。它不仅可以处理任何编程语言开发的应用程序,还不需要应用程序的源代码。这确保了在复杂多样的工业环境中的实用性。
TCSA 的关键思想是将函数调用栈时间序列化以形成TCStack,并基于忙等待同步的机制识别每个线程的连续相同调用栈。然后,TCSA 根据函数在 TCStack 中的执行时间对线程进行分组,并区分线程的用户模式或内核模式。最后,TCSA 获取包含候选忙等待线程的争用组。这使我们能够捕捉忙等待线程并缩小时间范围。对于每个争用组,TCSA 合并相同的调用栈并建模可能发生同步争用的调用链。此外,TCSA 生成线程的时间图,这可以帮助工程师区分哪些线程正在执行或等待。
TCSA 可以帮助定位符合忙等待机制的各种性能问题。我们验证了 TCSA 在不同延迟关键应用服务中出现的以下忙等待模式的有效性。
- 自旋锁争用:Redis 中自旋锁对同一资源的竞争。
自旋锁(Spin Lock)是一种轻量级的锁机制,用于在多线程编程中实现同步。自旋锁的工作原理是,当一个线程试图获取锁时,如果锁已经被其他线程持有,它不会进入休眠状态,而是会持续地检查锁的状态(即“自旋”),直到锁可用为止。
- 自旋锁的原理
自旋锁的基本原理是忙等待,即线程在等待锁时不断地循环检查锁的状态,直到锁被释放。与传统的互斥锁(如pthread mutex)不同,自旋锁不会导致线程进入休眠,从而避免了上下文切换的开销。- 主要特点
- 低开销:自旋锁避免了线程的上下文切换,因此在短时间锁定的情况下具有低开销。
- 忙等待:自旋锁采用忙等待机制,占用CPU时间直到获取锁。
- 适用场景:适用于锁持有时间短的场景,不适用于长时间持有锁的场景,因为忙等待会浪费CPU资源。
- 链式自旋锁争用:MySQL 中自旋锁链式调用引起的性能错误。
链式自旋锁(Queue-based Spin Lock)是一种改进的自旋锁实现,旨在解决传统自旋锁在高并发环境下的性能问题。链式自旋锁通过维护一个等待线程的队列,减少了自旋等待带来的资源浪费和公平性问题。
- 链式自旋锁的原理
链式自旋锁的基本思想是将等待获取锁的线程组织成一个队列,每个线程在其自己的本地变量上自旋,而不是在全局变量上自旋。这种方式减少了总线争用,提高了系统的整体性能。- 常见实现
一种常见的链式自旋锁实现是MCS锁(Mellor-Crummey and Scott Lock)。MCS锁通过链表结构将等待线程串联起来,每个线程只自旋等待其前驱线程释放锁。- MCS锁的工作流程
- 获取锁:
线程请求锁时,创建一个节点并将其插入到等待队列的尾部。
如果线程是队列中的唯一节点,它立即获取锁;否则,它自旋等待其前驱节点通知其锁可用。- 释放锁:
线程释放锁时,检查其后继节点。
如果存在后继节点,则通知其锁可用;否则,更新全局锁状态为未被持有。- MCS锁的优点
- 减少总线争用:通过将自旋操作限定在本地变量上,减少了全局变量上的总线争用。
- 公平性:线程按顺序获取锁,避免了“饥饿”现象。
- 可扩展性:在高并发环境下具有良好的可扩展性。
- Futexes:MySQL中futexes相同哈希结果引起的性能抖动。
futex是”Fast Userspace Mutex”的缩写,它允许用户空间的线程在内核的最小干预下实现高效的同步操作。futex的基本思想是通过用户空间的自旋锁或轻量级锁来避免昂贵的系统调用,只有在需要等待的情况下才进入内核态。
- futex的工作原理
- 用户空间操作:线程首先在用户空间尝试获取锁,如果成功则不需要进入内核态。
- 内核辅助:如果用户空间操作失败(即锁已经被其他线程持有),线程会通过futex系统调用进入内核等待。
- 唤醒机制:当锁被释放时,内核会唤醒等待的线程,使其重新尝试获取锁。
这种机制极大地减少了用户空间和内核空间之间的上下文切换,从而提高了锁操作的性能。- InnoDB中的锁
InnoDB是MySQL默认的存储引擎,支持事务和行级锁。在InnoDB中,锁机制非常重要,用于保证数据的一致性和并发控制。以下是InnoDB中常用的锁类型:
- 互斥锁(Mutex):用于保护共享资源,确保只有一个线程可以访问某些关键数据结构。
- 读写锁(RW-Lock):允许多个线程同时读取,但只允许一个线程写入。
- InnoDB中的futex优化
InnoDB利用futex来实现高效的互斥锁和读写锁。通过使用futex,InnoDB可以减少线程在锁争用时的上下文切换,从而提高并发性能。以下是InnoDB中使用futex的一些典型场景:
- 锁等待:当一个线程需要等待锁时,使用futex进入内核等待,从而避免忙等待造成的CPU资源浪费。
- 锁唤醒:当锁被释放时,通过futex唤醒等待的线程,使其重新尝试获取锁。
- Java 虚拟机(JVM)内的safepoint检查:JVM 内 safepoint 设置不当引起的性能下降。
Safepoint 是JVM中一个安全停顿点,在这个点上所有线程都会暂停执行,允许JVM执行需要全局一致性的操作。JVM在特定情况下(如垃圾收集、线程栈扫描等)需要暂停所有应用线程,以确保这些操作在一致的状态下进行。
- Safepoint的触发条件
典型的触发Safepoint的操作包括:
- 垃圾收集(Garbage Collection)
- 线程栈扫描
- 类重定义(Redefine Classes)
- 断点和单步调试操作
Safepoint的工作原理
进入Safepoint
当JVM需要进入Safepoint时,会向所有线程发出暂停请求。线程在到达下一个Safepoint检查时会暂停执行。Safepoint检查点通常设置在以下地方:
- 方法调用
- 循环回边(Loop Back Edges)
- 异常处理
线程在这些地方检查是否需要进入Safepoint,如果需要,线程会暂停执行,等待全局操作完成。
- 全局操作
所有线程暂停后,JVM可以安全地执行全局操作,如垃圾收集或线程栈扫描。在Safepoint期间,应用线程不进行任何用户代码的执行,确保全局操作的一致性和安全性。- 退出Safepoint
全局操作完成后,JVM会解除线程的暂停状态,允许线程继续执行用户代码。线程恢复执行的位置就是它们进入Safepoint的检查点。
背景和动机
背景介绍
在云系统中,延迟关键的应用越来越广泛,包括各种场景。工业环境中通常会为应用服务设定响应时间阈值。这些应用服务通常通过忙等待同步实现快速响应,以确保任务成功完成或满足客户需求。忙等待同步的问题在于,超过预期的等待时间可能会导致性能错误,如服务执行失败或资源浪费。
当线程等待资源时,会出现两个问题:首先,CPU没有被释放,导致资源浪费;其次,多线程对共享资源的竞争可能导致优先级反转,高优先级线程因低优先级线程的阻塞而延迟。这可能导致延迟关键应用的性能下降(如响应时间增加)或服务崩溃。工程师通常收集整个系统的线程性能数据来定位错误。然而,工业环境复杂,许多服务线程同时运行。对Redis集群和MySQL集群两个环境的调查中,即使在短时间内也有数十万甚至数百万的函数调用栈。检测大量数据中的忙等待同步是具有挑战性的。
挑战
我们总结了在工业环境中定位忙等待同步性能错误所面临的挑战:
- 数据增长的爆炸性与高频采样: 为了定位和诊断性能问题,工程师们通常会延长采样时间并提高采样频率以收集性能数据。长时间和高频率的采样会导致数据量急剧增长,甚至在短短几秒钟内,尤其是在复杂的操作环境中(如前文所述的场景)。现有的实践依赖于手动缩小故障排查的范围,这效率低下。
- 定位开销的限制: 对于延迟关键应用(如云游戏和电子商务),性能非常重要。这些场景对性能错误分析方法有严格的开销要求。即使在某些情况下可以启用调试模式,但在调试模式下定位性能异常并不具有可扩展性。这会带来较大的存储和性能开销。现有方法在性能错误定位过程中无法满足这些开销要求,如存在较大的运行时开销。
- 不同编程语言中的各种忙等待模式: 忙等待同步错误可能出现在不同编程语言实现的延迟关键应用中。不仅有编程语言的差异,还有各种忙等待模式,包括不同编程语言或软件堆栈中实现忙等待同步的机制。先前针对特定忙等待模式或特定编程语言的方法或工具,无法很好地适应实际需求。
- 缺乏源代码支持: 对于云系统中的延迟关键应用,几乎不可能重新编译项目以获取调试信息。特别是在容器或 KVM(基于内核的虚拟机)上运行的应用,通常只会将二进制代码部署到生产环境。此外,由于业务保密性,客户通常拒绝向性能团队提供应用的源代码以进行性能错误定位。
方法
TCSA概述
TCSA 是一种通过时间调用栈(TCStack)自动定位忙等待同步性能错误的实用高效方法。图3展示了 TCSA 的框架。TCSA 包括三个组件:时间序列化、过滤和建模。

时间序列化组件负责收集运行系统上线程的函数调用栈信息,并将这些调用栈进行时间序列化以获得 TCStack。过滤组件首先通过 TCStack 识别线程的连续相同调用栈,接着根据地址空间区分线程的执行模式,最后将线程划分到不同的争用组中。建模组件主要为每个争用组的线程自动建模调用链,并生成时间图。
时间序列化组件
我们利用Linux perf工具收集系统上线程的函数调用栈信息。在大多数情况下,用户不愿接受在生产环境中进行连续采样的开销。通常,监控工程师会提供数据收集的开始和结束时间(即可能发生性能异常的时间段)。在设置好数据收集脚本的参数(采样开始和结束时间、采样频率和采样周期)后,TCSA会自动在满足条件时触发采样。
对于收集到的性能数据,关键步骤是将函数调用栈进行时间序列化以构建TCStack。我们将每个线程记录的时间戳作为时间轴上的一个点。时间轴上的每个时间点对应线程的一个性能记录,其中包含时间戳、命令、线程ID(tid)、CPU和调用栈等字段。所有线程的函数调用栈构成了时间轴上的 TCStack。
在实现过程中,TCSA将收集的原始性能数据作为输入。经过时间序列化组件处理后,输出的是TCStack。我们使用TCSA定位第II-B节描述的性能错误作为使用示例。TCSA 将收集的性能数据进行时间序列化,得到如图4所示的 TCStack。每个时间点对应性能记录的时间戳值。每个性能记录包含的字段如前所述。例如,record1表示在时间戳为93534709.851606时,线程ID为10588的redis-server进程在CPU=17上执行了一个调用栈。

过滤组件
识别连续相同调用栈: 使用时间序列性能数据进行异常定位的挑战之一是如何确定滑动窗口的大小。但从操作系统的角度看,当线程存在忙等待同步争用时,这些线程会始终在CPU上等待资源,或频繁调度进出CPU检查资源的可用性,而线程执行的函数大概率不会发生变化。因此,我们利用线程的连续相同调用栈来识别忙等待同步的性能错误。
我们定义了以下概念用于实现。在本文中,调用路径表示由一个或多个函数组成的调用栈。连续相同调用路径指的是线程在 TCStack 中的两个相邻调用路径相同。默认情况下,我们比较线程调用栈中的所有函数,识别连续相同调用路径。识别后,我们会得到四个新字段:cicp(连续相同调用路径)、cicp_number(cicp的数量)、ts_begin(cicp的开始时间)和 s_end(cicp的结束时间)。这里ts_begin和ts_end的单位为秒,采集时间为相对值。
这一步的输入是 TCStack,识别后的输出是线程的连续相同调用路径列表,如图5所示。以第一条记录为例,该记录表示在时间 ts_begin = 93534716.853439 到 ts_end = 93534717.443050 之间,线程ID为2820的redis-server进程在CPU=17上连续执行相同的调用路径,且在 TCStack 中连续相同调用路径的记录数量为1176。

根据执行时间分组线程: 对于识别后的结果,我们根据执行时间将具有交叉执行时间的线程分组。对于具有连续相同调用路径的线程,我们使用开始和结束时间戳(ts_begin 和 ts_end)作为分组依据。TCSA 将执行时间重叠的线程分成同一组,我们称之为争用组。
TCSA 以识别结果(如图5所示)为输入进行分组。分组后,我们可以得到多个争用组,每个组包含执行时间重叠的不同线程,如图6所示。TCSA细粒度地根据执行时间分组线程,尽量避免将竞争不同资源的线程分到同一争用组。

区分执行模式: 在用户模式下,线程通常设置有优先级,以确保重要线程及时获得共享资源。然而,在内核模式下,通常不允许线程抢占资源。我们发现使用忙等待同步访问资源的线程在内核模式下会互相干扰。因此,对于每个争用组中的线程记录,我们根据执行函数的地址区分线程的执行模式。TCSA 根据 Linux 操作系统识别函数地址的位数(32位或64位),然后通过函数地址值所在区间区分执行模式,如图7所示。

建模组件
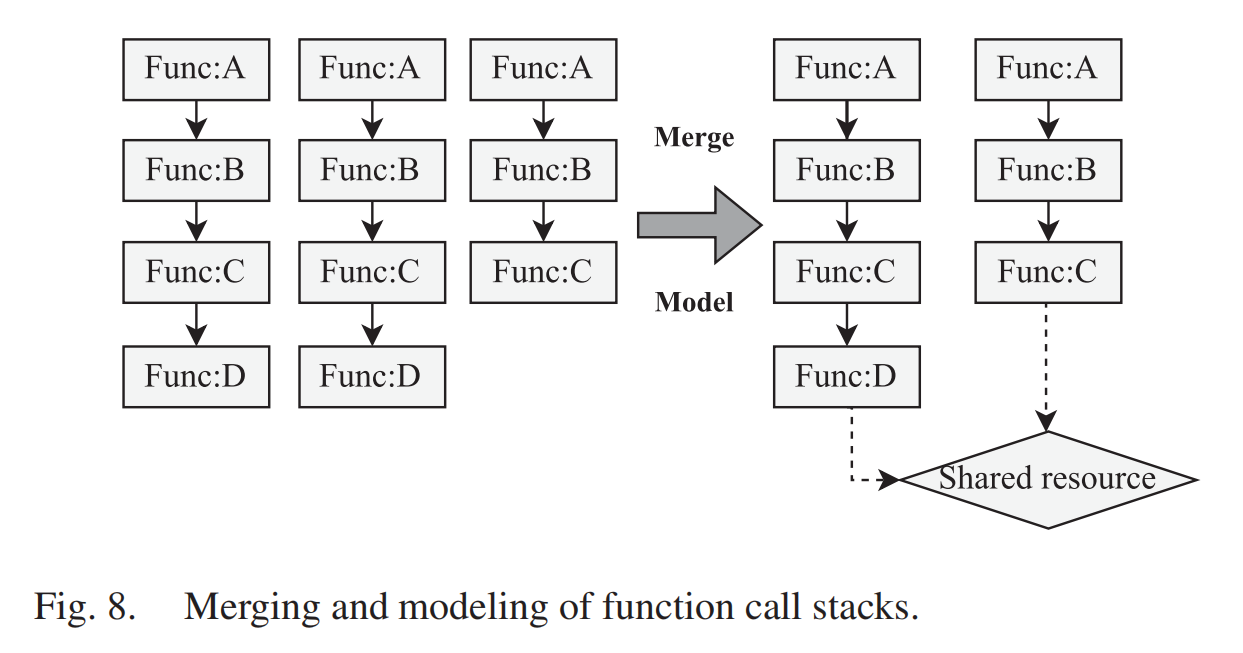
建模函数调用链: 为了进一步减少重复数据记录并发现线程之间的关系,我们将不同线程的函数调用栈建模为调用链。当不同线程在同步过程中等待相同的资源时,线程的函数调用栈与共享资源之间形成等待循环。TCSA合并相同的调用路径,并在调用路径上寻找重叠或交叉,以更直观地展示竞争线程之间的关系,如图8所示。需要注意的是,为了避免误导,我们不会将短的连续相同调用路径合并为长的连续相同调用路径。即使调用路径相同,线程可能也在等待不同的资源。如果TCSA识别出两个具有相同调用栈的不同线程处于同一争用组,则值得工程师进行检查,因为具有相同调用栈的线程通常在竞争相同的资源。
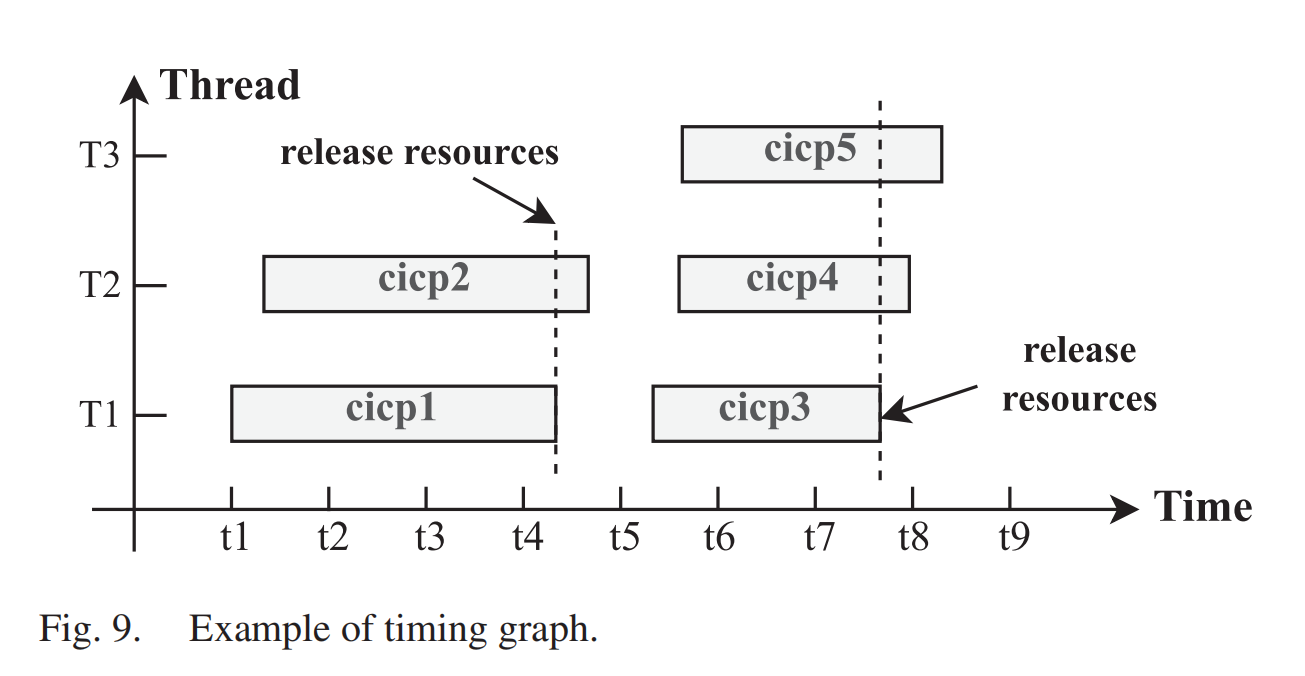
生成时间图: 通过时间图,我们可以定位可能正在执行的线程和在CPU上等待的线程。x轴代表时间,y轴代表线程的连续相同调用路径。通过用不同颜色标记不同的连续相同调用路径,我们可以直观地区分线程是否在执行相同的调用路径。与火焰图不同,时间图直接反映了函数调用栈在时间上的执行信息,如图9所示。TCSA识别出的具有连续相同调用路径的所有忙等待同步线程可能处于等待或运行状态。TCSA将具有最早时间戳的线程视为资源持有者,其他线程视为等待者,因为具有最早时间戳的线程可能最先访问共享资源。我们可以看到,时间图底部的线程(如 T1)可能在持有资源并执行,而上方的线程(如 T2 和 T3)可能在等待。
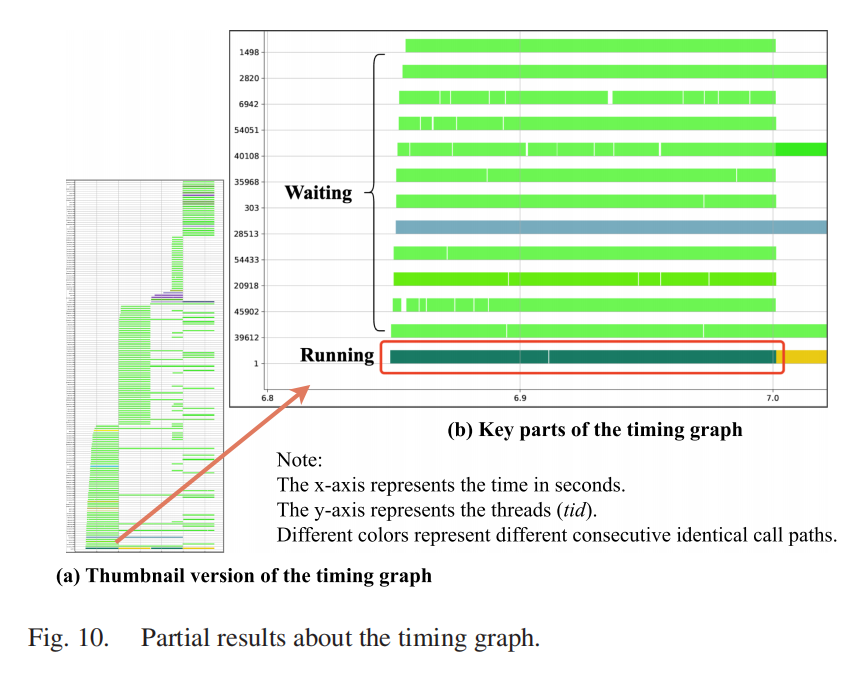
生成时间图的目的是发现是否存在 “垂直切割”现象,即一个线程的连续相同调用路径变化时,导致其他线程也发生变化。TCSA 自动生成的 Redis 案例时间图如图10所示。我们可以清楚地看到,当 systemd 线程执行结束时,其他线程(包括 Redis 线程)的等待状态消失。因此,可能是 systemd 线程在持有共享资源后执行,导致包括 Redis 线程在内的其他线程在等待资源。
定位结果
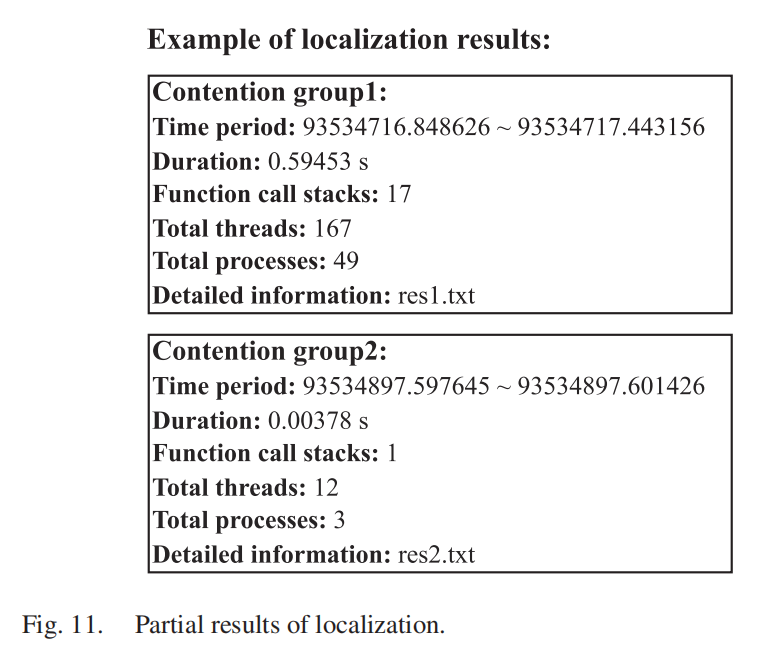
通过自动定位和过滤,TCSA 输出检测到的忙等待同步性能错误的结果。定位结果包括线程列表和时间图,列表记录了多个争用组的信息。对于每个组,包括可能发生忙等待同步争用的时间段(从 ts_begin 到 ts_end)、线程总数、函数调用栈数量、进程数量以及具体结果存储在哪个文本文件中。
实际使用中TCSA输出的定位结果如图11所示。工程师可以通过检查定位结果来找到性能错误。例如,工程师可以检查存储在res1.txt文件中的具体线程和函数调用栈,以分析这些线程是否是性能错误的原因。
可能影响有效性的威胁
内部威胁
识别参数是有效性的关键内部威胁。在参数选择方面,我们基于忙等待同步机制比较了不同参数设置的检测效果。根据实验结果,我们默认比较线程调用栈中的所有函数,而不仅仅是正在执行的调用栈顶端函数。当然,我们在TCSA的实现中支持自定义参数,以识别不同的连续相同调用路径。在检测新的案例时,我们有信心检测出忙等待同步性能错误。然而,提供绝对的保证是困难的。
此外,不同实现类型的同步会影响检测结果。TCSA可能将连续占用CPU执行正常循环的线程识别为忙等待同步性能错误。为了减少这种影响,我们区分了线程的执行模式,并能够找到通常在内核模式下竞争的线程。在实践中,我们发现工程师可以很容易地对检测结果进行判断。因为工程师可以结合检测结果和线程的时间图进行判断,基于线程执行连续相同调用路径的时间重叠关系,很容易得出结论。
外部威胁
多线程执行中的非确定性对性能错误定位有一定影响。在多线程环境中,性能异常本质上是非确定性的。TCSA通过自动化定位提高了性能异常解决的效率。
性能数据的质量对检测结果的准确性至关重要。通常,在收集性能数据时,采样频率设定为 999 Hz,每个样本的采样时间设定为 5 分钟。这样的设置不仅能够捕捉到毫秒级的性能错误,还能避免单个数据样本存储容量过大。在我们面对的实际案例中,这种参数设置效果良好。工程师可以根据实际工业环境调整采样时间和频率。需要注意的是,高频采样会增加开销,因此在实际环境中需要在频率设置和相关开销之间进行权衡。
云服务系统中应用类型的影响是另一种外部威胁。对于某些非延迟关键的应用(如大数据中的批处理),几毫秒的波动可能不会被用户察觉。然而,对于延迟关键的应用,毫秒级的响应时间抖动是严重的性能问题。我们的方法在如 Redis 服务、MySQL 服务和实时业务的 Java 应用程序等云服务系统中已验证有效。